Redes Neuronales Multicapa Con Aprendizaje Supervisado
Ejemplo de una función de aproximación (fap2D.m)
En este ejemplo de MATLAB aproximamos dos funciones de dos variables,
![]() o
o ![]()
![]()
Usando un perceptrón de dos capas,
| (3.25) |
Los pesos del Perceptrón, Wh, Wy, son entrenados usando el algoritmo básico de backpropagation.
Empezaremos con la especificación de la red neuronal (fap2Di.m):
p = 3 ; % Número de entradas (2) mas la entrada de el bias
L = 12; % Número de señales ocultas (con bias)
m = 2 ; % Número de salidas
La estructura de la red es la siguiente:
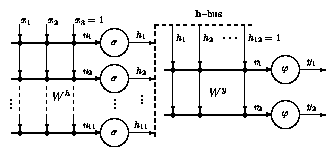
Dos señales serán aproximadas por un Perceptrón de dos capas:
![]()
![]() donde
donde ![]()
El dominio de la función es un cuadrado ![]()
Se tomaran muestras de las funciones para el entrenamiento y se colocaran en una rejilla de 16 ×16. El código para formar las matrices de muestras X y D es el siguiente:
na = 16; N = na^2; nn = 0:na-1; % Número de casos de entrenamiento
Especificación del dominio de las funciones:
X1 = nn*4/na-2; % na puntos de -2 en dos, desde (4/na)=.25 a (2-4/na)=1.75
[X1 X2] = meshgrid(X1); % especificación de los vértices de la matriz X1 y X2 son na por na
R=(X1.^2+X2.^2+1e-5); % R (rho) es una matriz cuadrática de distancias de los vértices de la matriz al punto original.
D1 = X1.*exp(-R); D = (D1(:))'; % D1 es na por na, D es 1 por N
D2 = 0.25*sin(2*R)./R ; D = [D ; (D2(:))']; %D2 es na por na, D es una matriz 2 por N de 2-D vectores
El dominio de los puntos de muestras es el siguiente:
X1=-2.00 -1.75 ... 1.50 1.75 X2=-2.00 -2.00 ... -2.00 -2.00
-2.00 -1.75 ... 1.50 1.75 -1.75 -1.75 ... -1.75 -1.75
. . . . . . . . . . . .
-2.00 -1.75 ... 1.50 1.75 1.50 1.50 ... 1.50 1.50
-2.00 -1.75 ... 1.50 1.75 1.75 1.75 ... 1.75 1.75
Recorriendo las columnas X1 y X2 y colocando el bias, obtenemos la matriz de entrada X la cual es p ×N:
X = [X1(:)'; X2(:)';ones(1,N)];
Los ejemplares de entrenamiento son los siguientes:
X = -2.0000 -2.0000 ... 1.7500 1.7500
-2.0000 -1.7500 ... 1.5000 1.7500
1.0000 1.0000 ... 1.0000 1.0000
D = -0.0007 -0.0017 ... 0.0086 0.0038
-0.0090 0.0354 ... -0.0439 -0.0127
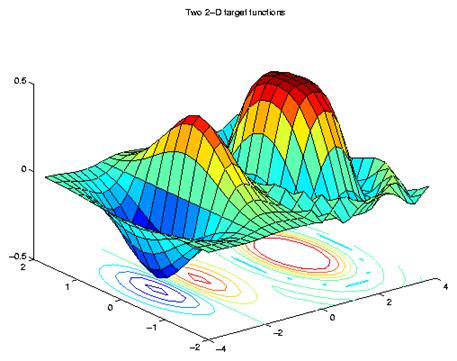
La función a ser aproximada se puede ver en la Fig. 3.11.
surfc([X1-2 X1+2], [X2 X2], [D1 D2])
Inicializando la matriz de pesos aleatoriamente:
Wh = randn(L,p)/p; La matriz de pesos de la capa oculta Wh es L ×p
Wy = randn(m,L)/L; La matriz de pesos de la capa de salida Wy es m ×L
C = 200; % máximo numero de épocas de entrenamiento
J = zeros(m,C); % Inicialización de la función de error
eta = [0.003 0.1]; % Ganancia de entrenamiento
El ciclo principal (fap2D.m):
for c = 1:C
El paso hacia adelante:
H = ones(L-1,N)./(1+exp(-Wh*X)); % Señales ocultas (L-1 x N)
Hp = H.*(1-H); % Derivadas de las señales ocultas
H = [H ; ones(1,N)]; % bias
Y = tanh(Wy*H); % señales de salida (m x N)
Yp = 1 - Y.^2; % Derivadas de las señales de salida
La retroalimentación:
Ey = D - Y; % Los errores de salida (m x K)
JJ = (sum((Ey.*Ey)'))'; % El error total después de una época
% de aproximación m x 1
delY = Ey.*Yp; % Señal de salida delta (m x K)
dWy = delY*H'; % Actualización de la matriz de salida
% dWy es L x m
Eh = Wy(:,1:L-1)'*delY % La propagación hacia la capa oculta del
error
% Eh es L-1 x N
delH = Eh.*Hp ; % Señal oculta delta (L-1 x N)
dWh = delH*X'; % Actualización de la matriz oculta
% dWh es L-1 x p
La actualización de los pesos:
Wy = Wy+etay*dWy; Wh = Wh+etah*dWh;
Las dos funciones de aproximación son graficadas después de cada época. Ver la Fig. 3.12 de la aproximación final.
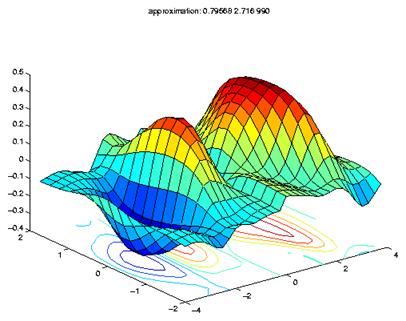
D1(:)=Y(1,:)'; D2(:)=Y(2,:)';
surfc([X1-2 X1+2], [X2 X2], [D1 D2]) J(:,c) = JJ ;
end % fin del entrenamiento
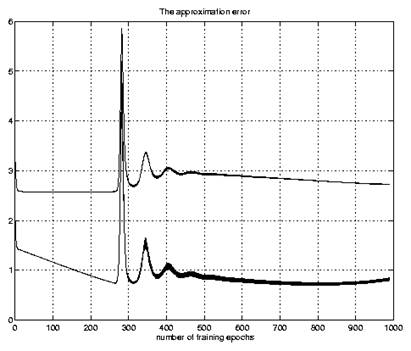
La suma del error cuadrático al final de cada época de entrenamiento es guardado en una matriz de 2 × C y mostrado en la Fig. 3.13.